Research
Today’s machine learning and artificial intelligence are limited by their costs — Training a model can easily take million of dollars, while acquiring, cleaning, and improving the underlying datasets to enforce model quality, fairness, and robustness is no cheaper. These costs come from different, closely-coupled sources: (1) the staggering amount computation, storage and communication that these models need, (2) the cost of infrastructure ownership in today’s centralized cloud, (3) the cost of data acquisition, cleaning, and debugging and associated human costs, (4) the cost of regulation compliance, and (5) the cost of operational deployment such as monitoring, continuous testing, and continuous adaptation.
The key belief behind my research is that we need to bring the costs down, by orders of magnitude, in all these fronts to bring ML/AI into a trustworthy and democratized future. In order to achieve this goal, our research focuses on building machine learning systems, enabled by novel algorithms, theory, and system optimizations and abstractions. Our research falls into two directions.
Project Zip.ML: Distributed and Decentralized Learning at Scale

 Distributed learning with system relaxations: Decentralization, Asynchronization, Compression
Distributed learning with system relaxations: Decentralization, Asynchronization, Compression
- Also available in Pytorch Lightening (
BaguaStrategy)! - Main System Reference: BAGUA: Scaling up Distributed Learning with System Relaxations, VLDB’22.

- Main Theory Reference: Distributed Learning Systems with First-order Methods, 2021. — A summary of our explorations on the theory side over the years at NeurIPS [‘17a, ‘18, ‘22a, ‘22b] and ICML [‘18a, ‘18b, ‘19, ‘20, ‘21] .

 Deep Recommendation Models at 100 Trillion Parameter Scale
Deep Recommendation Models at 100 Trillion Parameter Scale
- Main Reference: Persia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters, SIGKDD’22.
- Blog from Google Cloud: Training Deep Learning-based recommender models of 100 trillion parameters over Google Cloud
![]() OpenGauss DB4AI
OpenGauss DB4AI  In-Database Machine Learning with deep physical integration
In-Database Machine Learning with deep physical integration
- Main Reference: In-Database Machine Learning with CorgiPile: Stochastic Gradient Descent without Full Data Shuffle, SIGMOD’22.
 LambdaML
LambdaML  Distributed machine learning over serverless infrastructure
Distributed machine learning over serverless infrastructure
- Main Reference: Towards Demystifying Serverless Machine Learning Training, SIGMOD’21.
Project Ease.ML: Data-centric ML DevOps
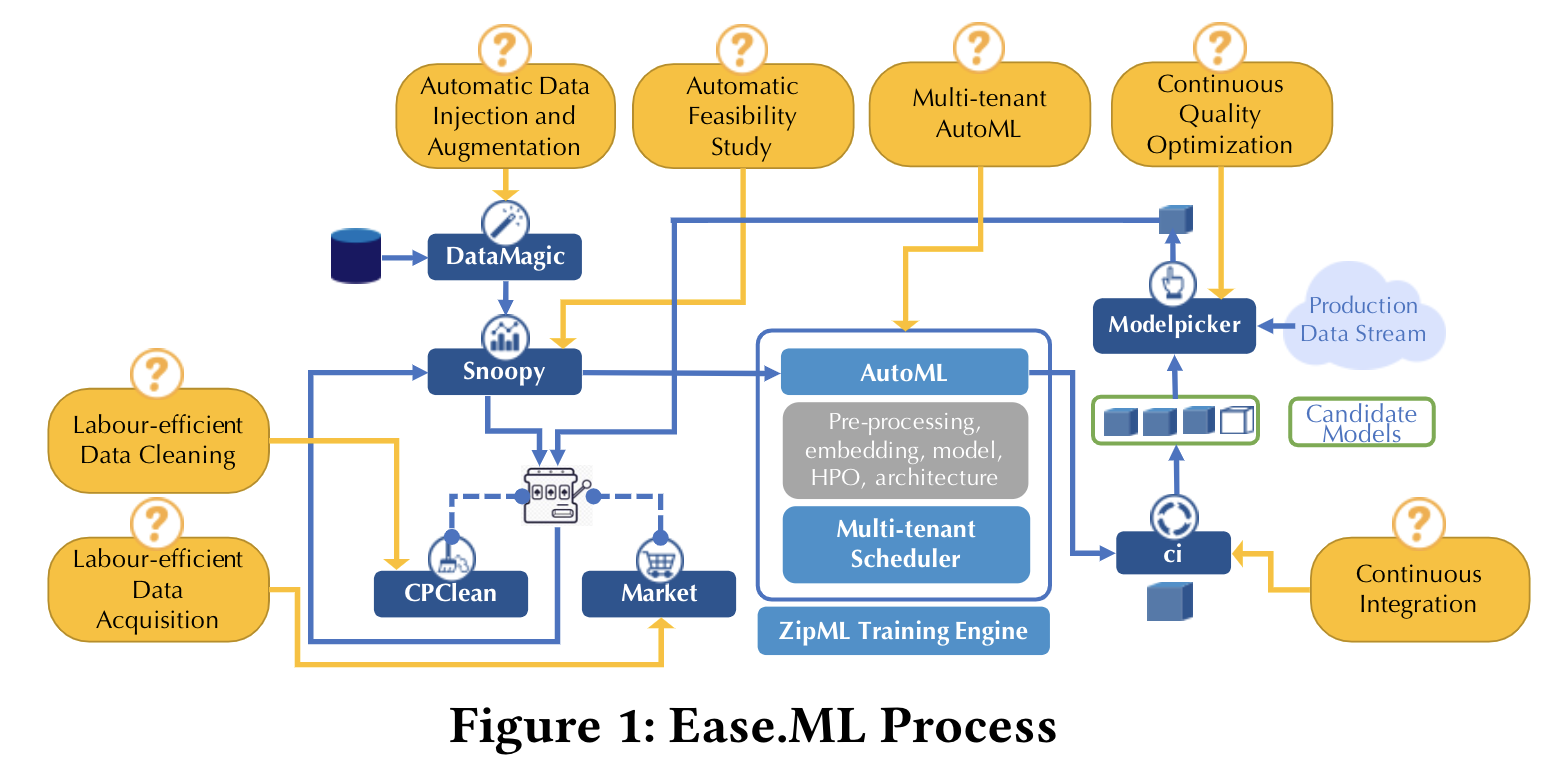 Ease.ML Family End-to-end Lifecycle management for ML DevOps: Rethinking Data Quality for Machine Learning
Ease.ML Family End-to-end Lifecycle management for ML DevOps: Rethinking Data Quality for Machine Learning
- System Overview: Ease.ML: A Lifecycle Management System for MLDev and MLOps, *CIDR’21.
- Ease.ML/DocParser
 Data Parsing and Ingestion
Data Parsing and Ingestion- :Main Reference: DocParser: Hierarchical Structure Parsing of Document Renderings, AAAI’19.
- Ease.ML/Snoopy
 Automatic Feasibility Study for ML
Automatic Feasibility Study for ML- Main Reference: Automatic Feasibility Study via Data Quality Analysis for ML: A Case-Study on Label Noise, ICDE’22.
- Ease.ML/DataScope
 Data Valuation and Debugging for ML
Data Valuation and Debugging for ML - Ease.ML/AutoML
 Multi-tenant AutoML
Multi-tenant AutoML- Main Reference: Ease.ml: towards multi-tenant resource sharing for machine learning workloads, VLDB’17.
- Ease.ML/CI
 Rigorous Testing and CI/CD for ML
Rigorous Testing and CI/CD for ML- Main Reference: Continuous Integration of Machine Learning Models with ease.ml/ci: Towards a Rigorous Yet Practical Treatment, *SysML’19.
- Ease.ML/ModelPicker
 Data-Efficient Continuous A/B Testing for ML
Data-Efficient Continuous A/B Testing for ML- Main Reference: Online Active Model Selection for Pre-trained Classifiers, AISTATS’21.